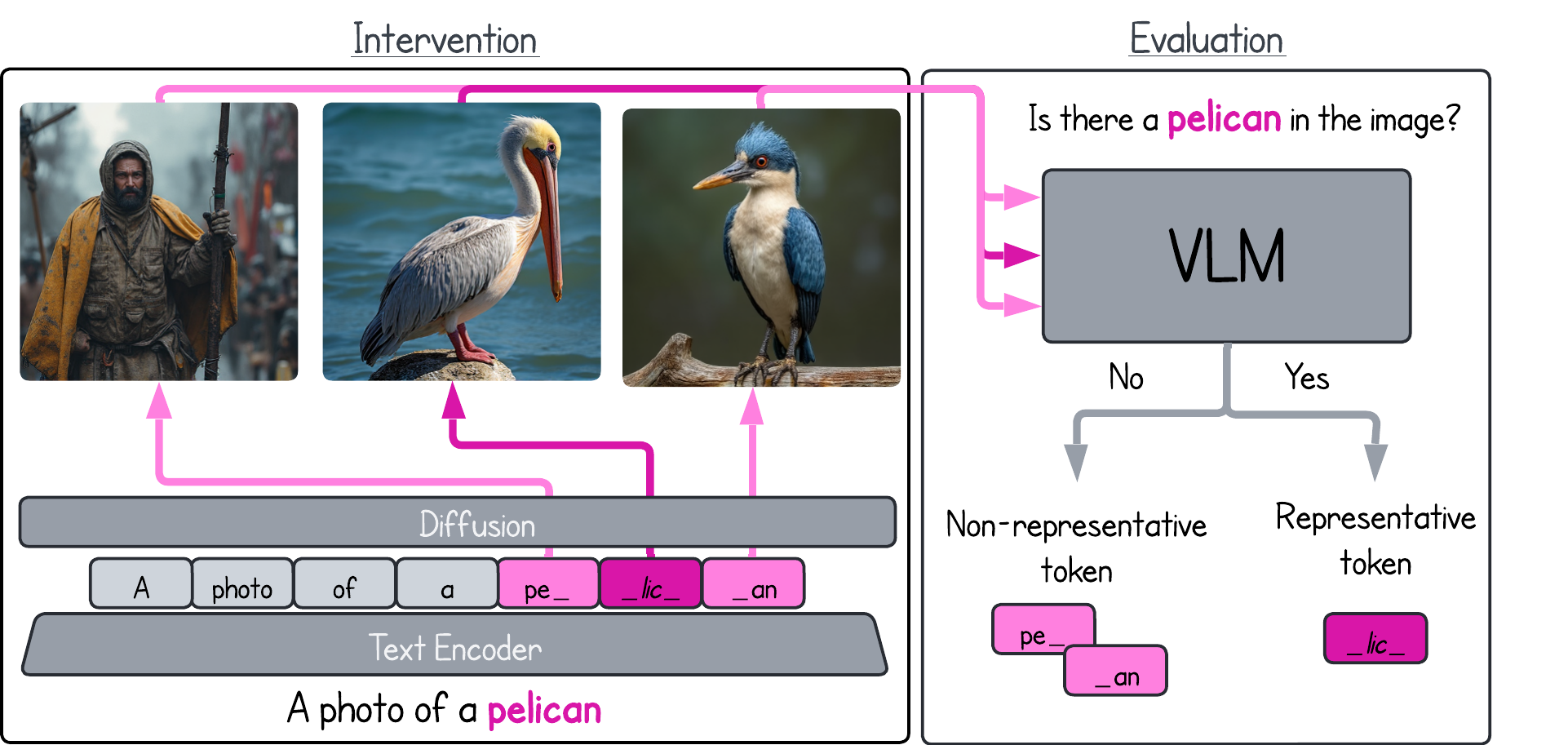
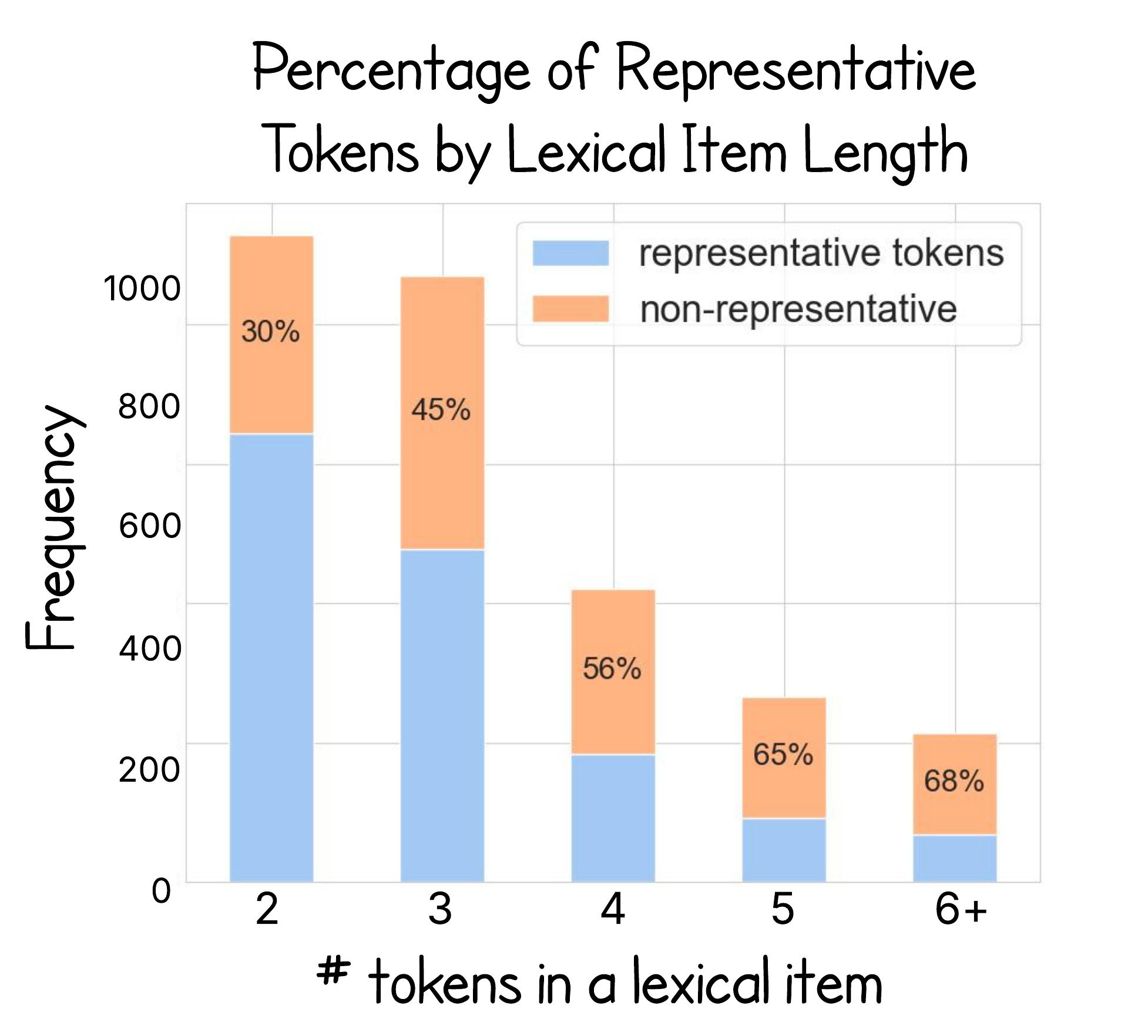
- Concentrated Information: In most cases, a lexical item’s meaning is concentrated in just one or two tokens.
- Redundancy Reduction: Removing redundant tokens improves image generation accuracy, lowering errors by 21%.
- Semantic Leakage: In 11% of cases, tokens unintentionally leak information between unrelated items, potentially leading to misinterpretations.
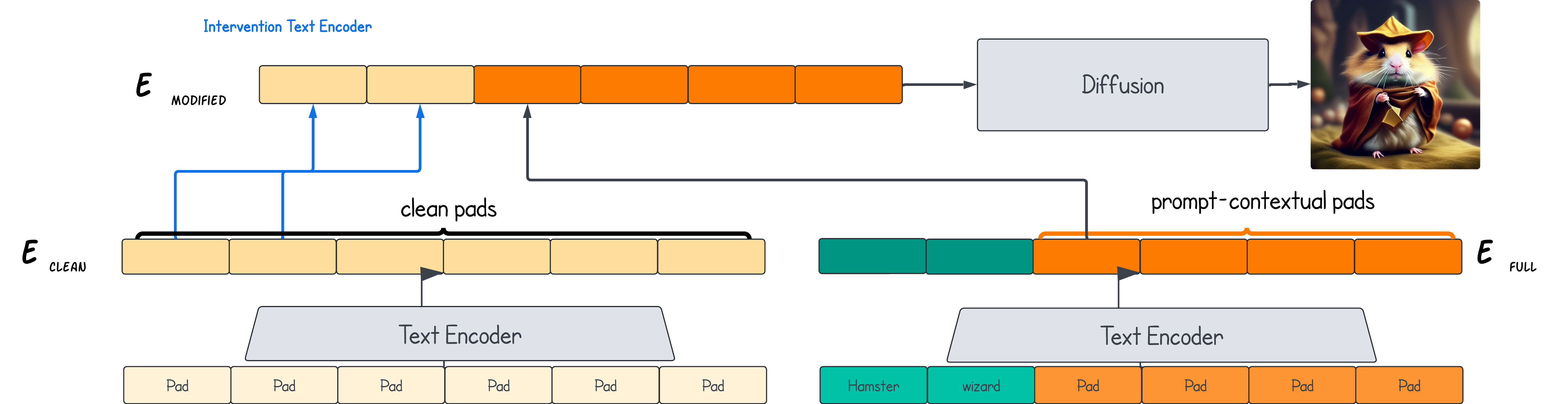
- Effective Patching: Replacing leaked token representations with their uncontextualized versions mitigates semantic leakage by 85%.
- Efficient Token Identification: A simple k-NN classifier predicts redundant tokens with 92% precision, enabling practical improvements in T2I pipelines.
- Catastrophic Negligence: In about 7% of cases, a lexical item is accurately encoded but fails to appear in the final image, highlighting a disconnect between the encoder and the decoder.
Motivation
Despite the impressive advances in text-to-image models, several key issues still persist:
- Missing Attribute Binding: In prompts such as “a pink colored giraffe,” the model may fail to accurately apply the pink attribute to the giraffe, generating a normal giraffe instead.
- Semantic Leakage: For example, a prompt like “a person wearing a cone hat is eating” can mistakenly merge the concept of the hat with the act of eating—generating an ice-cream cone hat.
- Catastrophic Neglect: Sometimes, as with “a tuba made of flower petals,” the primary object (the tuba) may be completely omitted, leaving only flower petals in the resulting image.
Traditionally, most approaches have addressed these challenges from the diffusion model's perspective—by tweaking the cross-attention mechanism or optimizing image latents. While these methods can mitigate certain errors, they do not solve all cases.
This observation raises a fundamental question: Could these issues originate earlier in the pipeline, within the text encoder itself?

Middle: “a pink colored giraffe” (attribute binding is missing).
Right: “a person wearing cone hat is eating” (semantic leakage from eating to the cone hat).